Am letzten Wochenende im September war ich, wie schon in den letzten Jahren (2024, 2023, 2022), für ein langes Wochenende bei der Web Engineering Unconference in Palma de Mallorca.
Im Gegensatz zu einer normalen Konferenz gibt es kein im Vorfeld festgelegtes Programm. Jeder der Teilnehmer kann ein eigenes Thema mitbringen und vorstellen. Ich hatte etwas halbherzig ein Thema vorbereitet, aber als am Vorabend der Reise mein Laptop gestreikt hat, habe ich das als Zeichen gesehen und bin ohne Computer gereist.
Nachdem ich am Freitag Nachmittag im Hotel eingecheckt hatte, holte ich erst einmal den Spaziergang nach, den ich in den letzten Jahren nicht geschafft hatte. Zwei Blocks hinter dem Hotel beginnt der Parc des Castell de Belver („Burg des schönen Blicks“) und der Name hat seine Berechtigung. Nachdem ich den bewaldeten Berg über holperige Pfade hoch spaziert war, bot sich von der Burg ein traumhafter Blick über die Bucht von Palma.
Über den Dächern von Palma
Beim abendlichen Eröffnungsumtrunk wurde klar, dass sich deutlich weniger als die maximal möglichen 100 Teilnehmer angemeldet haben. Man merkt, dass die fetten Zeiten vorbei sind. Auf der einen Seite machen sehr stark gestiegene Preise für Flug und Hotel die Teilnahme mittlerweile wirklich teuer. Da hilft das günstige Veranstaltungsticket auch nicht mehr so richtig. Der Hauptgrund ist jedoch, dass auch in der IT mittlerweile die Rezession angekommen ist. Die Umsätze sind geschrumpft, Projekte wurden eingestellt. Leute entlassen. Dass eine Agentur drei oder vier Leute schickt kommt nicht mehr vor und auch das Sponsoring kam wohl erst auf die letzte Minute zustande.
Einreichung der Themen am Samstag Morgen
Aber wie einer der Organisatoren gesagt hat: Es kommt nicht darauf an, wie viele Leute kommen, sondern ob es einen guten und interessanten Austausch gibt und man neue Ideen und Sichtweisen mitnimmt. Bei den Sessions, die ich besucht habe, hat das gut geklappt.
Die Themen an Tag 1
„Is our Industrie bleeding out? How do you feel“ JP startete eine Diskussion um die Herausforderungen und Veränderungen insbesondere im Agenturgeschäft, das nicht nur unter dem konjunkturellen Einbruch leidet, sondern auch unter dauerhaften veränderten Rahmenbedingungen: Geänderte Geschäftsmodelle, der Trend weg von individuellen Shops hin zu Plattformen und Hyperscalern, die Veränderungen durch AI und etlichem mehr.
„Software architecture in 2028„ Stefan Priebsch moderierte eine Diskussion darüber, was Softwarerachitektur ausmacht. Dabei wurden sowohl unterschiedliche Aspekte wie Struktur von Code und Daten, als auch viele weiche Faktoren, wie Zuständigkeiten (ownership) genannt.
„Palantir, Spotify, Oracle… where do you draw the line? – ethics in development„ Julia Dorandt moderierte das große Thema Technik und Ethik. Wo sieht man sich selbst, wie weit ist man bereit mitzugehen, auch wenn einem die Richtung nicht passt. Wo sind rote Linien, die man nicht überschreiten will? Verlässt man eine Firma, wenn einem das politische Engagement der Führungsebene nicht passt? Wenn man feststellt, dass das Produkt doch mehr Nebenwirkungen hat, als Gedacht? Wie verändert sich diese Sichtweise , wenn man wirtschaftlich unter Druck steht oder sich die politische Weltlage ändert? War ein Auftrag von Rheinmetall vor dem Ukrainekrieg Jahren problematischer als heute oder ist es vielleicht andersherum?
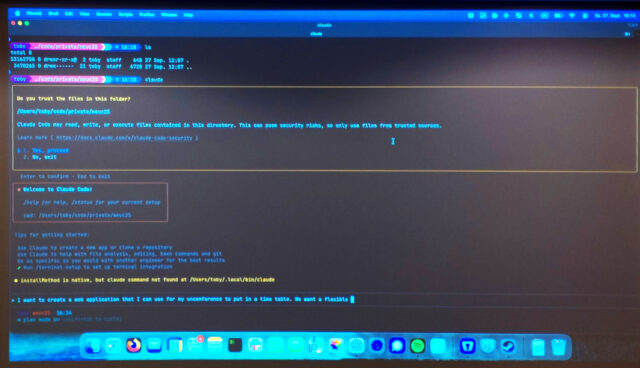
„AI tools, models, experience exchange„ Tobias Schlitt zeigte anhand zweier Beispiele, wie er zur Zeit AI nutzt. Zunächst beauftragte er ChatGPT damit, mit Hilfe der Deep Research Funktion Informationen zur WEUC zu sammeln, zusammenzufassen und zu strukturieren. Das dauert eine Weile, aber es kam ein gute Dossier dabei heraus, in dem die Kernaussagen mit Quellenangaben belegt wurden. Danach erzeugte er mit Hilfe von Claude.AI eine kleine rudimentäre Webanwendung, mit der Themen einer Veranstaltung organisiert werden können.
Tobias demonstriert Vibe Coding mit Claude AI
„Do we need a TPO?„ Judith Andreesen, Evgenij und Olli stellten die Frage, ob man in Projekten einen Technischen Product Owner benötigt. In der Diskussion wurde deutlich, dass die Einführung einer solchen Position meist auf andere ungelöste organisatorische Probleme zurückzuführen ist, die man zuerst lösen sollte.
Kein schlechte Mischung für den ersten Tag: Einmal Technik, die demonstriert wurde, einmal Technik auf abstraktem Level, einmal Management, einmal Ethik und einmal Business.
Die Themen an Tag 2
Auch am zweiten Tag ging es interessant weiter. Es kamen einige Themenvorschläge hinzu, die sich aus den Gesprächen am Vorabend ergeben haben.
„Architectural roleplay (live action)„ Stefan Priebsch moderierte ein Rollenspiel, bei dem wir interaktiv die Anforderungen an eine Transaktionssystem herausarbeiten sollten. Das Thema war scheinbar einfach und übersichtlich: „Gäste, die ein Restaurant besuchen“.
Wie zu erwarten, war das Ganze dann doch komplizierter, je mehr man ins Detail ging. Beispiel: Der Kellner nimmt die Bestellung auf. Dazu hat er vorher den Gästen die Menükarte gegeben. „Woher kommt die Karte und das war darauf steht?“ Offensichtlich gibt es hier einen Subprozess, der eine gewisse Komplexität aufweist. Das wurde notiert und dann weitergemacht. So etwas passiert noch ein paar Mal.
Interessant wurde es, da einige Mitspieler etwas zum Scherzen aufgelegt waren. Da fiel „spontan“ die „Champagnerflasche“ vom Tisch, woraufhin eine Person aus dem Orga Team, die eigentlich nur kurz in den Raum kam um Fotos zu machen, zu seiner Verblüffung mit dem Worten begrüßt wurde „Wir müssen jetzt sauber machen – Du bist der Lappen“. Er nahm es mit Humor und spielte gleich mit. Wir haben bei der Session viel gelacht und einiges an neuen Methoden gelernt.
„Open Telemetry“ Rainer Schuppe beschäftigt sich schon seit langem mit dem Thema „Observability“ – also der technischen Überwachung von komplexen Systemen. Er gab uns eine Einführung in die Hintergründe, Geschichte und Konzepte von Open Telemetry und zeigte, wie man diese Tools nutzen kann.
„B2B – How to sell B2B – Companies to sell online?“ Da ich früher im eCommerce Bereich mehrere B2B Kunden betreut hatte, war ich neugierig, was sich in den letzten 10 Jahren getan hat. Spoiler: Weniger, als ich erwartet hatte. Einen besonderen Dreh bekam die Diskussion dadurch, dass sie am Pool stattfand. Einige wollten die Diskussion sogar im Pool führen aber das haben wir dann doch gelassen.
Die Session spontan nach draußen an den Pool verlegt
Das letzte Thema „Vibe coding of an application using FrankenPHP, CouchDB and HTMX“ ist ein hervorragendes Beispiel, wie auf einer Uncoference spontan ein neues Thema kreiert werden kann. Es gab bereits Themenvorschläge, zu FrankenPHP, CouchDB und HTMX, die aber nicht genügend Stimmen bekamen.
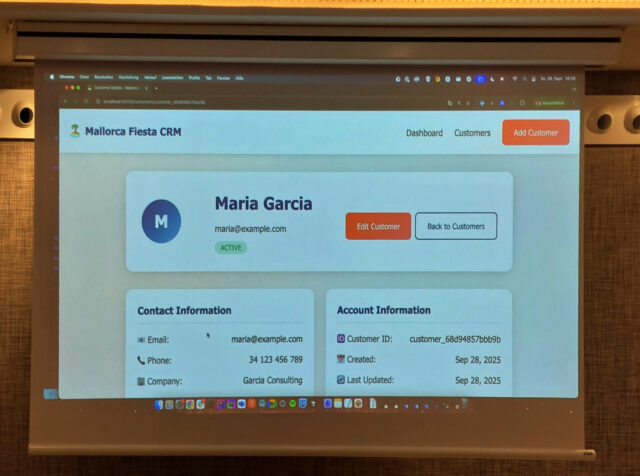
Also hat ein Teilnehmer all das genommen, zusammengerührt und eine spontane Vibe Coding Session mit Hilfe von AI daraus gemacht. Am Ende kam tatsächlich ein Prototyp einer kleinen Web Applikation dabei heraus. Auch hier wurde viel gelacht, weil die Anforderungen absichtlich sowohl inhaltlich, als auch technisch ziemlicher Kokolores waren und die Interaktion mit der KI ziemlich lustig ausfiel.
Ergebnis der Vibe Coding Session: Eine kleine Kontaktverwaltung
Interessant war die sehr unterschiedliche Rezeption: Die meisten Anwesenden waren wie ich Entwickler. Wir hatten unseren Spaß durch die Reaktionen und Fehler der KI und haben das alles nur halb-ernst genommen.
Ein Anwesender war aber Produkt Manager und der war ganz aus dem Häuschen, dass nach 40min. tatsächlich ein benutzbarer Prototyp vorhanden war. Wir haben ihn dann etwas eingebremst, indem wir darauf hinwiesen, dass der Code weder sauber, noch sicher, noch langfristig wartbar war.
Davor, dazwischen und danach
Wie immer bei dieser Art Veranstaltung ist das offizielle Programm aber nur ein Teil. Ebenfalls sehr wichtig sind die spontanen Gespräche am Rand, während des gemeinsamen Essens und Trinkens. Zudem sind an zwei Abenden auch einige Bekannte aus der eCommerce Szene zum Schnack dazugestoßen die gerade auch auf Mallorca waren. Dieser „Off-Track“ Austausch ist sozusagen das Salz in der Suppe. Sehr wichtig und sehr schön.
Das Wochenende habe ich mit einer kleinen Truppe in einer Tapas-Bar in der Altstadt von Palma gemütlich ausklingen lassen. Wirklich gemütlich – denn die Abende sind zwar immer noch nicht völlig abstinent, aber weitaus weniger verheerend als früher. Wir werden halt alle älter…
Gute kleine Tapas Bar in der Altstadt
Neben all den schönen Dingen, die jede der bisherigen Veranstaltungen auszeichnete, gab es aber auch wieder einen weniger schönen Punkt: „Können wir die WEUC auch im nächsten Jahr nochmal durchführen?“ Die Herausforderungen bei Orga, Sponsoring, Wahl des Ortes und der Zeit werden durch die schwierige wirtschaftliche Lage nicht einfacher. Wir werden sehen.
Ich hoffe darauf, dass es 2026 auch noch einmal klappt.
In diesem Jahr habe ich wieder die Web Engineering Unconference besucht, die vom 20. bis zum 22. September in Palma de Mallorca stattfand. Mittlerweile eine lieb gewonnenen Gewohnheit und auch dieses Mal waren die Vorträge, Diskussionen und Gespräche interessant und anregend.
Blick über Palma – einige Wolken und viel Sonne
Das ist umso schöner, weil Anfang des Jahres durchaus dunkle Wolken am Veranstaltungshimmel zu sehen waren. Das eingespielte Orga Team der letzten Jahre hatte aufgehört. Das neue Team musste sich erst finden, weshalb die Ankündigung recht spät kam. Zwischenzeitlich waren Flug- und Hotelpreise ordentlich gestiegen und das alles in einem wirtschaftliche schwierigeren Umfeld.
Erfreulicherweise wurden trotz der halbierten Teilnehmerzahl auch dieses Mal wieder viele interessante Themen präsentiert. Die informellen Gespräche jenseits der eigentlichen Konferenz waren anregend und vielschichtig.
Teilnehmer bei der Themenfindung
Das kommt sicherlich auch daher, dass dieses kleine, aber feine Branchentreffen keine herkömmliche Konferenz ist sondern eine Unkonferenz. Hier wird nicht zwischen Zuhörern und Vortragenden unterschieden, sondern jeder kann seine eigenen Themen mitbringen und vorstellen. Alle zusammen stimmen dann ab, welche Themen angenommen werden.
Das kann auch recht spontan sein. Einen eigenen Vortrag hatte ich dieses Mal nicht vorbereitet. Mir ging aber seit längerem ein Thema durch den Kopf, das ich nicht so recht zu fassen bekam. Am Vorabend habe ich das einigen Leuten gegenüber erwähnt und die Reaktion war immer „Mensch, das ist doch relevant und spannend – mach was dazu!“
Das Thema ist ständig steigende Komplexität.
Genauer die Frage, weshalb wir dazu tendieren, Systeme immer komplexer zu machen, bis sie nicht mehr richtig funktionieren oder aktualisiert werden können. Konkreter Anlass war das Refactoring einer umfangreichen Software, aber das Problem ist nicht technisch, sondern eher universell.
Die üblichen Ansätze, steigende Komplexität in den Griff zu bekommen, laufen darauf hinaus, neue Werkzeuge und Verfahren zu etablieren, um die Komplexität zu managen. Leider wird das Problem dadurch nicht gelöst, sondern nur verschoben und die Gesamtkomplexität steigt durch die neuen Tools sogar noch weiter an.
Oft wäre es besser, stattdessen die Komplexität zu reduzieren, aber diese Weg wird fast nie gegangen. Mich interessierte die Frage, weshalb das so ist. Zumal das kein technisches Problem ist. Wir sehen dieselben Muster bei allen möglichen Organisation in der Wirtschaft und auf staatlicher Seite.
Session „Komplexität“ mit Julia und Dirk (Foto von Maria Adler)
Ich hatte also Szenarien und Fragen mitgebracht. Passenderweise hatte Julia Dorandt (Beratung Judith Andresen) einen Vortrag vorbereitet, in dem sie Strategien vorstellte, die Individuen nutzen, um in einem komplexen System handlungsfähig zu bleiben. Stichwort „fight flight freeze fawn„. Wir haben also zusammen einen Slot genutzt, in dem ich einleitend die Fragestellung aufgeworfen habe und Julia anschließend die Theorien aus der Verhaltenspsychologie erläutert hat.
Für das Thema haben wir viel positives Feedback bekommen. Ich konnte jedoch leider keine konkreten Handlungsempfehlungen ableiten. Als ich in der darauf folgenden Woche in meiner Firma davon erzählte, wurde das Thema aufmerksam aufgenommen und ich bekam einige gute Hinweise auf Quellen zu dem Thema.
Weitere weiche Themen auf der WEUC waren Neurodiversität, „Talking to people“ und Kommunikation in schwierigen Organisationsstrukturen.
Technische Vorträge gab es natürlich auch.
Alexander M. Turek hielt einen Vortrag zu „Strict PHP“. Was bedeutet das, wozu ist es gut und weshalb es nicht reicht, das einfach im Programm zu deklarieren.
Rainer Schuppe (Oberservability Heroes) stellte Open Telemetry vor – ein Framework zur Erfassung von Messdaten. Er demonstrierte Einsatzzwecke und Möglichkeiten zur Datenauswertung.
Und natürlich gab es auch in diesem Jahr wieder einige Slots zum Thema „Künstliche Intelligenz“. Während KI in den vergangenen zwei Jahren eher als enormes Potential gesehen wurde, nimmt nun die tatsächliche Nutzung sprunghaft zu. Beispiele:
Automatisierte Website Analyse
Suche in und Zusammenfassung von großen Dokumentensammlungen
Unterstützung beim Programmieren und Einsatz bei personalisierter Akquise.
Automatische Erstellung von „best of presentation“ Videos. Der Teilnehmer kommentierte das so: „Das Ergebnis sind so eine Art TikTok Videoschnipsel von unseren Vorträgen.“
Bei generativer KI zur Erzeugung von Bildern und Videos sind die enormen Verbesserungen der letzten zwei Jahre augenfällig, aber es gibt noch immer zu viele eigentümlichen Artefakte. Dennoch wurde gerade die Zusammenarbeit von Runway (AI basierte Generierung von Videos) mit der Filmproduktionsfirma Lionsgate bekanntgegeben.
Joschua Ziethen (Yet Another Agency) zeigte interessante Beispiele zum Einsatz von KI Toolchains mit Hilfe von make.com. Zudem hat mich der Bastian Hofmann (Qdrant) zum Thema Vektordatenbanken sehr angesprochen.
Trotz des reduzierten Umfangs gab es also auch in diesem Jahr wieder reichlich spannenden fachlichen Austausch. Ein Teilnehmer meinte sogar, dass er es gut fand, dass wir in diesem Jahr nur zwei, anstelle von drei parallelen Tracks hatten, weil man so weniger verpasst.
Nur zwei anstelle von drei parallelen Tracks – aber interessante Themen
Es gibt also viel Positives zu berichten. Dennoch haben mir aber viele von meinen Buddies aus der E-Commerce Szene gefehlt. Ohne Marco, Lars, Fabian oder Thomas ist es nicht so ganz dasselbe. Andererseits habe ich darum bei der Abendgestaltung nicht über die Stränge geschlagen. Das ist dann wiederum ganz gut für die Gesundheit des alten Mannes.
Hat die WEUC noch Zukunft?
Die Diskussion, ob wir die Veranstaltung im nächsten Jahr weiterführen sollen, wurde einstimmig bejaht. Wir waren uns auch einig, dass 50 Teilnehmer die Untergrenze sind und wir eher wieder auf 75 bis 90 kommen sollten.
Diese zusätzlichen Teilnehmer wollen wir vorzugsweise in anderen Branchen als e-commerce und außerhalb von Deutschland finden, um die Diversität an Themen und Sichtweisen zu fördern. Denn trotz Englisch als Konferenzsprache wurde der Anspruch, eine internationale Konferenz zu sein, in diesem Jahr nur knapp erreicht.
Bei der Frage, ob es wieder Mallorca sein muss, gab es unterschiedliche Meinungen. Mir selbst ist das nicht so wichtig („Meinetwegen Kassel oder Bielefeld“), so lange sich eine gute Mischung aus Teilnehmern und Themen findet. Die überwiegende Mehrheit fand jedoch, dass die entspannte Atmosphäre und das Ambiente zum Erfolg der Veranstaltung beiträgt.
Da ist etwas dran. Das Besondere, weshalb ich jedes Jahr gerne wieder teilnehme ist die Offenheit, mit der hier Herausforderungen und Lösungsansätze besprochen werden. Im Gegensatz zu anderen Konferenzen, steht hier nicht Verkauf und Selbstdarstellung im Vordergrund, sondern ehrlicher Gedankenaustausch.
Zum Ende der Veranstaltung ein Zeichen zu setzen, sagte eine Sponsorin bereits die Unterstützung für 2025 zu. Nun ist es an uns, den längeren zeitlichen Vorlauf für eine gute Organisation und Medienarbeit zu nutzen.
Auf dass die Web Engineering Unconference 2025 wieder interessant, spannend und lehrreich wird.
Seit einiger Zeit ist künstliche Intelligenz ein allgegenwärtiges Thema. Ich bin da selber stets skeptisch gewesen. Jahrzenhnte lang was das Thema eher ein fahler Witz. Zudem – wie soll ich an künstliche Intelligenz glauben, wenn ich schon kaum an natürliche Intelligenz glaube? (siehe: Zustand der Welt)
Zynismus beiseite – letztlich ist KI nur „Statistik auf Speed“. Die Grundlagen sind mathematisch verblüffend banal. Das sollte jeder verstehen können, der sich durch das Abitur geboxt hat. Von neuronalen Netzen war auch bereits zu meiner Schulzeit in den 80ern die Rede. Der Grund, weshalb das Thema jetzt so abhebt, ist die Verfügbarkeit von früher unvorstellbarer Rechenpower und digitalen Datenbergen.
Man muss zugeben, dass das Feld gerade explodiert. Texte, Bilder und Videos werden nach allen Regeln der Kunst und Manipulation zurechtgelogen und -gebogen. Selbstfahrende Autos haben (in den USA) bereits Fähigkeiten, die sie durch normale Programmierung in den nächsten 50 Jahren nicht erreicht hätten. KI wird uns in den nächsten Jahren überrollen, wie es die Computer in den 80er und 90er Jahren gemacht haben. Millionen von Arbeitnehmern werden ihre Jobs verlieren – und zwar diesmal die hochqualifizierten Angestellten. Höchste Zeit also, sich das Ganze etwas näher anzusehen.
Erste Schritte zwischen „Wow“ und „Was zum Geier…“???
Bisher habe ich nur hier und da etwas Theorie gelesen, aber selbst noch nichts aktiv genutzt. Aus gegebenem Anlass beschäftige ich mich jetzt selber mit diesem Thema. Mein Ziel war es, eine Serie von Bildern inhaltlich analysieren zu lassen, und die Erkenntnisse zu verschlagworten. Dabei sollten nicht nur Objekte in den Bildern erkannt werden, sondern auch bestimmte Situationen, damit daraus Handlungsempfehlungen abgeleitet werden können.
Noch vor fünf Jahren hätte ich abgewunken und „unmöglich“ gesagt. Nun stehen mir etliche Werkzeuge aus der Microsoft Azure Cloud und GPT4 zur Verfügung. Die Anwendung ist nicht schwer zu programmieren, weil die eigentlich anspruchsvolle Arbeit ja von den Cloudservern erledigt wird.
Ich musste nur dafür sorgen, dass die Bilder nacheinander zur KI hochgeladen werden, die Antwort entgegennehmen und verarbeiten. Ach ja, und der „Prompt“ muss natürlich sinnvoll sein. Damit sagt man der KI, was sie machen soll – und zwar in natürlicher Sprache.
Erster Eindruck: Die Objekterkennung ist ziemlich gut. Man bekommt eine Liste von Dingen, die die KI auf dem Foto erkannt zu haben glaubt, zusammen mit einem „Confidence“ Wert. Ein Eintrag wie „Hardhat (confidence: 0.93)“ bedeutet sinngemäß: „Ich bin mir zu 93% sicher, dass dort ein Bauarbeiterhelm ist“. In diesem Fall war es zwar ein roter Ball unter einem Schreibtisch – aber da der Kontext „Baustelle“ war, ist das völlig in Ordnung. Da muss man halt später noch mal mit einer Plausibilitätsprüfung drüber. Die anderen Dinge wurden verblüffend korrekt erkannt.
Aus den Objekten alleine kann man aber noch nicht viel ableiten. Die Beziehung untereinander und der Kontext ergibt eine Einschätzung der Situation. Und auch die ist verblüffend gut gewesen.
So wurde gelobt, dass das Baugerüst ordentlich aufgestellt war und bemängelt, dass die Bauarbeiter keine ausreichende Schutzkleidung trugen. Selbst potentiell gefährlich Situationen wurden erkannt „Bauarbeiter unter schwebender Kranlast“. Sehr sehr beeindruckend.
Nun habe ich versucht die Analyseergebnisse selber weiter zu verarbeiten. Dazu müssen sie in einen standardisiertes Format gebracht werden. Das ist an und für sich kein großes Thema: Man analysiert den Rückgabetext und erzeugt daraus Schlagworte die mit dem Bild verbunden werden.
Dabei ist mir aber schnell einen Manko aufgefallen: Wenn ich der KI das identische Bild wieder und wieder vorlege, bekomme ich jedes mal andere Antworten. Das reicht von unterschiedlicher Wortwahl über unterschiedliche Reihenfolge und Gewichtung und tatsächlich sind auch die erkannten Sachverhalte nicht völlig identisch. Das ist ein Verhalten wie es Menschen in einer Diskussion zeigen würden. Leider ist es damit aber völlig ungeeignet um damit verlässliche Schlagwortlisten aufzubauen. Insbesondere wenn es um wirklich wichtige Themen wie Sicherheit geht und nicht nur um Smalltalk.
So bin ich gerade etwas hin- und hergerissen. Einerseits ist die Bildanalyse wirklich beeindruckend. Andererseits macht die mangelhafte Reproduzierbarkeit das vernünftige Arbeiten nahezu unmöglich.
Taugt das was? Ich weiß noch nicht so recht…
Neulich habe ich einmal irgendwo gelesen, KI sei nur ein stochastischer Papagei, der Intelligenz vorgaukelt. Man könnte natürlich etwas bösartig sagen, dass das auch für 85% der Menschen zutrifft.
Von solchen philosophischen Betrachtungen abgesehen, habe ich wahrscheinlich nur noch nicht die richtigen Schalter und Parameter gefunden. Ich bleibe erst mal am Thema dran…
Vom 22. bis zum 24. September fand die Web Engeneering Unconference in Palma de Mallorca statt. Bereits im letzten Jahr bin ich zu dieser Veranstaltung gereist, hatte damals eine ordentliche Portion Skepsis im Gepäck und wurde sehr positiv überrascht (siehe: „Web Engineering Unconference 2022„). Soviel vorneweg: Auch in diesem Jahr hat sich die Teilnahme für mich gelohnt.
Die Bucht von Palma de Mallorca
Natürlich ist Mallorca stets eine Reise wert aber das Besondere der WEUC liegt nicht nur am Ort, sondern vor allem an der Art der Veranstaltung. Die Teilnehmerzahl ist auf 100 begrenzt. Teilweise kennt man sich schon seit Jahren, es sind aber auch viele neue Gesichter dabei gewesen. Jeder kann ein Thema mitbringen und vorstellen. Daher weiss man im Vorfeld auch nicht, was für Vorträge oder Diskussionsrunden zu erwarten sind. In diesem Jahr hatte ich auch einen Vortrag vorbereitet, den ich erfolgreich gehalten habe – dazu weiter unten mehr.
Gemeinsames „Einschwingen“ am Vorabend in einer Bar in der City
Da der Teilnehmerkreis mittlerweile sehr international ist, galt das Motto „english only, please!“ – und zwar nicht nur für die Vorträge, sondern auch, beim gemeinsamen Essen und Trinken, damit jeder in interessante Gespräche einsteigen kann. Denn davon gab es reichlich.
Socializing
Diese Art Veranstaltung hat immer mehrere Ebenen: Zunächst natürlich die formelle Ebene des Informationsaustauschs in Vorträgen und Diskussionen während des offiziellen Programms.
Raucherpause zwischen den Vorträgen
Und dann gibt es die informelle Ebene: Gespräche zwischen den Pausen, sowie beim gemeinsamen Essen und Trinken. Das ist dann irgendwas zwischen vertiefenden fachlichen Gesprächen, Kontaktpflege und auch purem Spass. Einige Teilnehmer sind zum Beispiel zwischendurch kurz in den Hotelpool gesprungen, bevor die Veranstaltung weiterging.
Gemeinsames Abendessen zum Ausklang des ersten Tages
Ein gemeinsames Abendessen, um den ersten Veranstaltungstag ausklingen zu lassen, gehört dazu. Und die Frage „Are we going to the Shamrock afterwards?“ ist schon fast ein Running Gag. Diese irische Kneipe mit Livemusik ist nicht weit entfernt und dafür berüchtigt, dass man super bis in die Morgenstunden feiern kann. Da kommt man schnell in die Zwickmühle zwischen Geselligkeit und dem Ruf der Vernunft. Man muss ja am nächsten Morgen einigermaßen fit sein. Ich bin ja schließlich nicht mehr 20. Oder 30. Oder 40… (oh jeh…)
Irgendwann dann doch – Shamrock Irish Pub
Technische Themen
An zwei Tagen, in drei parallenen Tracks und 11 Timeslots gab es insgesamt 32 Vorträge und Diskussionen. Aus Platzgründen kann ich hier nur einige nennen:
Zu Beginn des ersten Tages: Sammlung der Themenvorschläge
Alexander M. Turek zeigte in seinem Vortrag „How much database abstraction do i need?“ die verschiedenen Ebenen von Datenbankabstraktion und wofür sie am besten einsetzbar sind, am Beispiel von Doctrine.
Ludovic Toison (NFQ Asia) sprach in „From DevOutch to DevOps“ darüber, wie man durch vereinfachtes GIT-Branching in Verbindung mit Feature Toggles von relativ langsamen Release Zyklen zu Continuous Deployment kommt.
Dennis Heidtmann (ScaleCommerce) präsentierte in „Smoxy – a new shortcut for better TTFB“ einen neuen Smart Proxy, der Load-Balancer, Page-Cache und Imageserver mit einer einfachen, übersichtlichen Nutzeroberfläche verbindet. Somit kann man einen Shop oder eine Symfony basierte Webapplikation sehr einfach erheblich beschleunigen – auch ohne Admin.
Es gab noch viele weitere interessante Themen (Sicherheit in Kubernetes Clustern, Data-Pipelines, was man aus Core-Dump aus gecrashten PHP Prozessen lernen kann etc.), die ich hier gar nicht ausführlich behandeln kann.
Das Top-Thema war natürlich Künstliche Intelligenz. Dazu gab es unter anderem eine Präsentation von Bertrand Lee (BrightRaven.ai) und mehrere Diskussionsrunden im Rahmen der Veranstaltung und in den informellen Treffen am Rande.
Im letzten Jahr gab es noch eine Vorführung der Bild-KIs Dall-E und Midjourney für die staunenden Teilnehmer. In diesem Jahr hatten die meisten bereits selbst mit KI herumprobiert. Die Frage war nicht mehr, ob die Technik genutzt werden wird, sondern nur noch darum wann und wofür sie bereits einsatzfähig ist. Relative Einigkeit herrschte in der Ansicht, dass wir Entwickler schon bald sehr viel anders arbeiten werden. Und der Zeithorizont ist sicher nicht 10 Jahre und vermutlich auch nicht mal 5, sondern eher noch kürzer.
Damit gehen interessante Fragen einher: Der Umgang mit „geistigem Eigentum“ (das schreibe ich bewusst in Anführungszeichen, weil ich das Konzept schon immer für dumm gehalten habe), natürlich die soziale Frage, denn frei nach Karl-Marx hat derjenige die Macht, der über die Produktionsmittel verfügt. Und während der Entwickler bisher der Produzent (von Code) ist, wird er im neuen Modell nur noch Nutzer von Wissen sein, das andere bereitstellen. Er wird also vom Produzenten zum Kunden degradiert. Weil das bereits viele verstanden haben, ist in der KI momentan enorm viel Bewegung im Open-Source Bereich, weil die Entwickler ihren Vorteil nicht einfach kampflos den Konzernen übergeben wollen.
Nicht-technische Themen
Für eine Entwicklerkonferenz gab es auch in diesem Jahr wieder viele nicht technische Beiträge.
Maria Adler (Yet another Agency) gab Anregungen, wie man besser und zufriedenstellender mit der weit verbreiteten Ticketsoftware Jira arbeiten kann.
Tobias Schlitt (commercetools) gab Beispiele, wie man Zusammenarbeit und Teamgeist fördern kann, wenn es keine Büro mehr gibt und nur noch remote gearbeitet wird. Denn das tun im e-commerce Bereich mittlerweile ziemlich viele Firmen.
Claudia Bender sprach über „Social Engineering, Cyber Security and Cyber Thread Intelligence“. Das Thema hat mich brennend interessiert, lag aber leider parallel zu einem anderen sehr interessantem Track.
Bei der Vorstellung der Themenvorschläge am ersten Tag sagten nämlich zwei Teilnehmer (die ich hier öffentlich nicht explizit nenne), dass sie gerne über Mental-Health-Probleme sprechen würden, falls das jemanden interessiert. Und darauf hoben sich fast von allen Teilnehmern die Hände. Am Ende wurden es sogar zwei Diskussionsrunden an Tag eins und zwei. Mein Eindruck ist, dass unter ITlern Probleme mit Depressionen und ähnlichem noch deutlich häufiger vorkommen als im Bevölkerungsdurchschnitt. Wir sind aber wohl jetzt an einem Punkt, an dem die Menschen zu verstehen beginnen, dass es sich um ernsthafte Krankheiten handelt, die man nicht einfach langfristig verstecken oder ignorieren kann.
Mein Vortrag
Wie eingangs erwähnt, hatte ich In diesem Jahr auch einen Vortrag vorbereitet. Zu Jahresbeginn fragte ich meinen Arbeitgeber, ob ich etwas zu unseren Erfahrungen der letzten Jahre erzählen darf/soll. Ich bekam grünes Licht und keine Vorgaben.
Herausgekommen ist ein Vortrag mit dem Titel „How to modernise a 12 years old web application – and the whole company“. Im Kern ging es darum, dass man ein für die Firma essentielles Softwareprodukt nicht modernisieren kann, ohne die Organisation drumherum und die Arbeitsweisen neu zu strukturieren.
Zu Beginn ist mir ein peinlicher technischer Fehler passiert, der für 5min Verspätung gesorgt hat und zudem habe ich noch nie einen öffentlichen Vortrag in englisch gehalten. Daher war ich ziemlich nervös. Mir wurde aber hinterher versichert, dass davon nichts zu spüren war und ich souverän rüberkam. Ich möchte mich hier nochmal ganz herzlich bei Alexander M. Turek für seine spontane technische Hilfe danken.
Endlich eine Stunde am Strand – nach dem Ende der Veranstaltung
Nach meinem Vortrag und dem Ende der Unconference hat die Zeit noch gereicht, um mit Freunden eine gute Stunde das Strandleben zu genießen, bevor wir später in einem hervorragenden Tapas-Restaurant in der Altstadt ein gemeinsames Abendessen zum Abschied genossen.
Abschiedsessen im La Taperia
An alle, die ich hier nicht explizit erwähnt habe: Ich habe jedes einzene Gespräch genossen und mich während der ganzen vier Tage keine Minute gelangweilt. Es gab unheimlich viele, gute Anregungen. Und selbst wenn ich Themen bereits kannte, konnte ich mich doch bestätigt fühlen, dass wir diese Dinge bei uns in der Firma bereits erfolgreich einsetzen.
Vom 9.-11. September fand in Palma de Mallorca die Web Engineering Unconference statt. Das ist ein Treffen auf dem sich 100 Menschen, die im Bereich Webentwicklung tätig sind, zu diversen Themen austauschen.
Parc de la mar, Palma de Mallorca in der Abendsonne
Das klingt etwas vage, was daran liegt, dass es sich um eine Unkonferenz handelt. Bei solch einer Veranstaltung gibt es zu Beginn keine feststehenden Vorträge und es ist noch nicht einmal klar, wer überhaupt etwas erzählen oder vorführen wird. Die Idee ist, dass jeder Teilnehmer auch Vortragender sein kann. Jeder kann Themen vorschlagen, über die sie/er/es reden oder etwas erfahren möchte. In einer gemeinsamen Abstimmung wird dann festgelegt, welche Themen genommen werden.
Wie der Veranstalter zu den Teilnehmern zu Beginn sagte: „We provide the rooms, the internet and food. You provide the content“.
Web engineering unconference – Veranstaltungsplakat
Der harte Kern der Teilnehmer und Sponsoren stammt aus der deutschen PHP E-Commerce Szene. Im Gegensatz z.B. zum E-Commerce Camp Jena ist die Web Engineering Unconference jedoch internationaler. Es waren Teilnehmer aus ganz Europa anwesend – darunter auch einige aus Mallorca ;-) und eine Gruppe kam sogar aus Vietnam. Die Konferenzsprache war daher Englisch.
Socializing
Bei solch einer Veranstaltung ist das gegenseitige Kennenlernen und die Kontaktpflege natürlich ebenfalls sehr wichtig, zumal sich aus diesen Gesprächen auch Themen für Vorträge entwickeln können. Fast alle waren bereits am Vortag angekommen, weil am Freitag Abend das erste Zusammentreffen in lockerer Umgebung stattfand: Einer Cocktail Bar am Rande der Altstadt von Palma.
Kurz vor dem Ansturm – Ginbo Cocktail Bar in Palma
Trotz des gemeinsamen „Vorglühens“ startete die Veranstaltung am Samstag Morgen pünktlich um 9:00. Die Vorträge und Workshops begannen nach der Themenfindung um 12:15, wobei es stets drei parallele Tracks gab.
Der Beginn der Unkonferenz – Die Sammlung der Themen
Themen
Herkömmliche Konferenzen sind häufig verkappte Verkaufsveranstaltungen, auf denen die Sponsoren in Vorträgen für ihre Produkte werben. Hier war es anders, weil Techniker unter sich waren, um über interessante Herausforderungen zu reden.
Von denen sind viele gar nicht mal technischer Natur. Es ging zum Beispiel über kulturelle Stolperfallen in internationalen Teams und Herausforderungen, wenn man selbst in anderen Ländern arbeitet. Zu dem Thema konnten die Mitarbeiter von NFQ Asia aus Vietnam einiges erzählen. Methoden zur Verbesserung der Vereinbarkeit von Familie und Arbeit in Zeiten von Homeoffice waren ebenfalls gefragt.
Moderation und Abstimmung zu den eingereichten Themen
Aber technische Themen kamen natürlich auch vor. Ich habe mir angesehen, wie sich das Headless CMS Storyblok in Shops und andere Websites oder Apps einbinden lässt.
Dass ein Vortrag zum Thema Zeit- und Datumsberechnungen mit viel Interesse aufgenommen wurde, können Nicht-Programmierer eventuell nicht ganz nachvollziehen. Jeder, der schon einmal damit zu tun hatte, weiß aber, dass es ein Thema mit kilometertiefen Abgründen ist. Stichworte wie Zeitzonen, Sommer-/Winterzeit, Schaltjahre, Julianischer und Gregorianischer Kalender können zu vorzeitig ergrauten Haaren beitragen.
Die Mitarbeiter von Shopware leiteten eine für mich sehr spannende Diskussion darüber, wie man komplexe Software automatisiert testet. Welche Arbeitstechniken und Tools sichern die Qualität bei vertretbarem Aufwand?
Mehrere Slots hatten die Grundlagen, wie Webhosting und Sicherheit in Containerarchitekturen zum Thema. Sie wurden u.a. von Mitarbeitern von Suse und Scale gehalten.
Mehrere Vorträge befassten sich im weiteren Sinne mit Künstlicher Intelligenz und Machine Learning. Es gab eine Live Vorführung der beiden viel besprochenen KI Bildgeneratoren Dall-E und Midjourney, die aus kurzen Textbeschreibungen Bilder generieren. Die Ergebnisse reichen von absurd über praktisch bis zu verblüffend. Schnell kam die Frage nach Einsatzszenarien, Zukunft von Grafikern und Anbietern von Stockfotos auf, aber auch inwieweit sich diese Technik mit dem Konzept des Urheberrechts verträgt.
Zwei Mitarbeiter von Scale führten den Stand ihrer Forschung vor, wie sie Machine Learning einsetzen wollen, um im Hosting möglichst in Echtzeit Schwachstellen (Sicherheitslücken, Angriffsszenarien, Performanceprobleme etc.) entdecken zu können.
Zwischendurch war für das leibliche Wohl gesorgt. Sowohl die Mittagessen am den beiden Konferentagen, als auch das Abendessen am Samstag fand im Restaurant des Konferenz Hotels INNSIDE Palma Bosque statt.
Innenhof des Hotels am AbendGemeinsames Abendessen als geschlossene Veranstaltung
Ein technisches und optische Highlight war die Vorführung des fotorealistischen 3D Konfigurators für Audi. Ursprünglich wurde die Technik entwickelt, um in den Showrooms per VR Brille jede mögliche Fahrzeugkonfiguration in 3D vorführen zu können. Dies wurde so weiter entwickelt, dass diese Echtzeitrenderings auch in jedem Webbrowser angesehen werden können. Grob zusammengefasst nimmt der Browser die Steuerbefehle entgegen, schickt sie per WebRTC an eine Renderengine in der Cloud, die das Ergebnis in Echtzeit berechnet und per Videostreaming an den Browser zurücksendet.
Die Wirkung ist verblüfend. Die Fahrzeuge lassen sich in jedem beliebigen Blickwinkel von außen und innen ansehen. Man kann jederzeit die Farbe, Räder und sonstige Ausstattung ändern, Türen und Kofferraum öffnen und schließen und sich das ganze in verschiedene Tag- und Nachtszenarien anzeigen lassen. Die Animationen sind butterweich, die Bildqualität extrem hochwertig, inklusive der Reflexionen der Umgebung.
Wie ich bereits schrieb, finden interessante Gespräche häufig abseits der Konferenzräume statt. So hatte ich mit einem Mitarbeiter von Innogames ein interessantes Gespräch über Personalführung und Karrierewege. Andere Gespräche hatten auch politische Dimensionen, wie Datenschutz, Mobilitätsverhalten und Umweltschutz auf individueller und struktureller Ebene. Und so schaffe ich die Überleitung zum Elefanten im Raum:
Denkt denn keiner an die Umwelt?
Wobei – die Umweltfrage ist eigentlich kein Elefant im Raum mehr, weil sie eben doch angesprochen wird.
Diese Web Engineering Unconference findet bereits seit einigen Jahren statt und natürlich wird die Frage diskutiert, ob es man überhaupt noch eine Veranstaltung abhalten sollte, bei der die meisten Teilnehmer mit dem Flugzeug anreisen.
In der Diskussion stand eine Verlegung an einen Ort, der zentraler liegt und per Bahn erreicht werden kann. Aufgrund der internationalen Teilnehmer ist es aber so, dass es diesen zentralen Ort nicht gibt und in beinahe jedem Fall mindestens ein Drittel per Flugzeug kommen würde.
Diese etwas unbefriedigende Situation hat man damit etwas abgemildert, indem pro Teilnehmer Umweltzertifikate für die Flugkompensation bezahlt wurden. Manche kommen auch mit Partnern/Famile und kombinieren das mit einem Urlaub, den sie ohnehin gemacht hätten. Viele haben ihre alltägliche Zwangsmobilität durch Homeoffice auch so heruntergefahren, dass sie nur noch wenige, aber dafür inhaltlich effektivere Treffen zum persönlichen Austausch, wie diese Veranstaltung besuchen.
Immerhin gibt es das Problembewusstsein und viele versuchen damit konstruktiv umzugehen. Das war auch an der sehr anregenden Diskussion zu merken, deren Ausgangspunkt war, wie wir Entwickler dazu beitragen können, dass unsere Software weniger Strom verbraucht. Zu Beginn wurde die Frage gestellt, welche der Frameworks und Libraries, die wir verwenden, den wenigsten Rechenaufwand erfordern. Aber schnell wurde klar, dass das nur ein kleiner Teil des Problems ist.
Sicherlich ist die Frage, weshalb ein einfacher E-Mail Client heutzutage eigentlich hundert mal soviel Speicher verbraucht, wie ein komplettes Betriebssystem vor 25 Jahren richtig und wichtig. Andererseits sind die hier erreichbaren Reduzierungen wenig wert, solange Geschäftsmodelle wie Streaming und KI zu explodierenden Datenmengen sorgen. Das oben erwähnte technisch sehr beeindruckende 3D Konfigurator von Audi ist zumindest in dieser Hinsicht sicherlich ein sehr schlechtes Beispiel.
Fazit
Ich war mir trotz Neugier zu Beginn nicht sicher, ob es eine gute Idee ist, an dieser Konferenz teilzunehmen. Ich arbeite ja bereits seit einiger Zeit nicht mehr im Bereich E-Commerce und befürchtete, dass mich die Themen nicht ansprechen würden. Die Teilnahme habe ich aus eigener Tasche bezahlt und für nur vier Tage zu fliegen, möchte ich eigentlich mittlerweile auch vermeiden.
Nach der Veranstaltung, den Tag noch in kleinem Rahmen gemütlich ausklingen lassen.
Zum Schluss war ich aber doch froh, teilgenommen zu haben. Die Bandbreite der Themen war groß, die Anregungen, die ich mitgenommen habe, waren vielfältig und die Gespräche, die ich hatte waren angenehm und interessant. Zudem habe ich liebe und interessante Menschen wiedergesehen. Ich bin mir sicher beim nächsten Mal wieder dabei zu sein und dann auch ein interessantes Thema vorzubereiten.
Was in den letzten Jahren (oder Jahrzehnten?) von vielen Angestellten dringend gewünscht aber von den meisten Firmen ignoriert oder sogar blockiert wurde, ging plötzlich ganz schnell, als Corona akut wurde: Homeoffice.
Immer mehr Büroangestellte wünschten sich die Möglichkeit zu Homeoffice. Aber selbst Firmen, in denen das eigentlich recht einfach umsetzbar gewesen wäre, sperrten sich häufig dagegen. Die Gründe zur ausgeprägten Präsenzkultur sind vor allem unflexible Organisation und Misstrauen gegenüber den Angestellten.
Das hat auf beiden Seiten zu einer gewissen Mystifizierung geführt: Viele Firmen sahen in Homeoffice eher eine dunkle Bedrohung. Vielen Angestellten erschien darin eine Verheißung zu höherer Lebensqualität.
Beide Extreme haben bei mir nur Stirnrunzeln hervorgerufen, weil ich bereits seit 2006 Erfahrung mit Homeoffice habe. Diese Erfahrungen haben jetzt in Deutschland hunderttausende Angestellte und deren Firmen im Expresstempo nachgeholt. Gut so, dann das entmystifiziert das Thema endlich.
Stufe 1 der Entmystifizierung: Homeoffice ist bedrohlich / befreiend
Alle Beteiligten haben viel gelernt. Die Firmen haben gelernt:
Homeoffice ist möglich und schnell einsetzbar.
Die Organisation kann (und muss) durch Homeoffice effizienter werden.
Videokonferenzen sind besser als Telefonkonferenzen und können Präsenzmeetings häufig ersetzen.
Angestellten erledigen die Arbeit auch dann, wenn nicht alle 10min der Chef zur Tür reinkommt.
Zur Zeit wird sehr viel Miete für ungenutzte Bürofläche gezahlt, obwohl die Arbeit weiterhin erledigt wird.
Die Angestellten haben gelernt:
Für Homeoffice braucht man verlässliches Internet und einen geeigneten Arbeitsplatz. Der Laptop auf dem Küchentisch genügt nicht.
Homeoffice und gleichzeitig Kinder betreuen, ist sehr anstrengend.
Mal einige Tage zu Hause zu sein ist nett. Immer zu Hause zu arbeiten nervt aber.
Auf die Dauer fehlen einem die Sozialkontakte zu den Kollegen (jedenfalls, wenn man ein nettes Team hat)
Stufe 2 der Entmystifizierung: Homeoffice ist gut für die Umwelt – oder?
Zeit für Stufe 2 der Entmystifizierung: Viele Befürworter propagieren, dass durch Homeoffice unnötige Pendelei entfällt und es deshalb aus Umweltschutzgründen positiv ist.
Das stimmt natürlich zunächst – zumindest in einer Phase, in der Homeoffice noch etwas neu und ungewohnt für die Angestellten ist. Ob das langfristig auch noch zutrifft, ist aber nicht so klar. Ich möchte meine Skepsis begründen. Zunächst der Blick zurück.
Unter Stadtplanern gab es bereits Ende der 80er / Anfang der 90er Jahre – also lange bevor das Internet für die Allgemeinheit zugänglich war – eine Diskussion darüber, wie der damals noch neue Einsatz von Computern und deren beginnende Vernetzung die Ansprüche an Raumnutzung, Verkehr und Energie verändern würde. Dabei wurden die heute sichtbaren Hauptfelder bereits richtig erkannt:
Onlinebanking ersetzt Bankfilialen
E-Commerce ersetzt Läden
Stark verändertes Kommunikationsverhalten durch neue Dienste wie Email und Videokonferenzen
Akten, Schriftverkehr und Transaktionen werden elektronisch verarbeitet und gespeichert. Ohne Papier sind sie nicht mehr ortsgebunden
Dadurch auch immer mehr Telearbeit
Aus damaliger Sicht erschien es logisch, dass die bevorstehende Welle der Entmaterialisierung die räumlichen Strukturen auflösen würde. Die überfüllten und teuren Innenstädte werden überflüssig und die Menschen ziehen sich in kleinere, überschaubare und naturnahe Orte zurück, zahlen weniger für das Wohnen. Städte werden aufgrund der abnehmenden Attraktivität und Funktion tendenziell leerer und gibt weniger Grund für Verkehr.
Die Menschen und der Rebound-Effekt
30 Jahre später wissen wir, dass genau das Gegenteil geschehen ist. Der Run auf die Metropolen hat erst recht eingesetzt. Die Zentralisierung und Verdichtung hat ständig zugenommen. Weite Landstriche haben so viel Abwanderung, dass dort die Grundversorgung nicht mehr aufrecht erhalten werden kann. Der Verkehr ist explodiert.
Die damals vollkommen logisch erscheinenden Prognosen erwiesen sich also als völlig falsch. Daher meine Skepsis.
Meine Prognose
Nun, da die Angst bei vielen Firmen vor dieser „neuen“ (Neu wie Neuland) Arbeitsweise schwindet und die Einsparpotentiale sichtbar werden, wird die Telearbeit vermutlich stark zunehmen – evtl. auch gegen den Willen der Mitarbeiter.
In meinem Bekanntenkreis habe ich nun folgende Erfahrung gemacht: Diejenigen, die bereits seit längerem ständig remote arbeiten, haben erkannt, dass das nicht unbedingt zu Hause in Berlin oder Bielefeld sein muss. Wenn man schon woanders sein kann, warum dann nicht auf Gran Canaria, am Schwarzen Meer oder in Thailand?
Das klingt zwar verlockend, führt aber zu einem CO2 intensiven Reiseverhalten. Und das gilt nicht nur für Solo Freelancer.
Ich habe 2010 das erste Mal eine Firma besucht, die in ihrem Office in San Francisco fast keine Angestellten mehr hatte: Automattic – die Firma hinter WordPress. Die Mitarbeiter, Entwickler, Grafiker und sonstige Angestellen lebten rund um den Globus verstreut. Matt Mullenweg erklärte, dass er die besten Leute bekommen will und die möchten nun mal nicht alle im Silicon Valley leben. Um den Mitarbeitern dennoch ein Gemeinschaftsgefühl zu ermöglichen, gibt es regelmäßig Events in allen Erdteilen, auf denen sie sich treffen.
Zwar sparen sich die Mitarbeiter so den normalen Arbeitsweg, benötigen zunächst weniger Energie und erzeugen weniger Emissionen. Durch die Teilnahme an den Events werden diese Effekte jedoch überkompensiert.
Ein langfristig positiver Umwelteffekt tritt also möglicherweise auch nicht auf.
Dirk Ollmetzer | Dienstag, 21 August 2018 | Development
Auf dem diesjährigen eCommerce Camp in Jena hatte ich einen Vortrag mit dem Titel „No KISS – we’re doing it wrong“ gehalten. Darin hatte ich mich kritisch mit aktuellen Trends in der Entwicklung von Webapplikationen auseinandergesetzt. Die Kernthese ist, dass in der Entwicklung der Trend zu Komplexität und Aufgeblähtheit geht. Alles was im Entwickler-Mainstream gerade angesagt ist, macht die Anwendungen fett, träge, angreifbar, schwieriger zu handhaben und aufwändig zu debuggen.
Ich hatte erwartet, mit dem Vortrag auf viel Widerspruch zu stoßen, aber das Feedback war seinerzeit wohlwollend. Das nehme ich nun zum Anlass, eine kleine Artikelserie mit dem Titel „Gegen den Strich“ zu diesem Thema zu schreiben.
Über Professionalität
Der Trend zur Komplexität und Fettleibigkeit ist so stark und wird so wenig hinterfragt, dass es mir zur Zeit wirklich die Lust an sogenannter „professioneller“ Softwareentwicklung vergällt.
Das betrifft Ebenen – angefangen von der Softwarearchitektur, über Designpatterns, benutzten Tools und Libraries, Entwicklungsmethoden, Deployment und Infrastruktur.
Ich habe gesehen, dass neue Produkte auf abstrakter Ebene eine hervorragende Architektur mitbringen und auf Codeebene derart akademisch aufgebläht sind, dass es mich bei dem Gedanken gruselt, in solch einem Codemoloch unter Zeitdruck Fehler suchen zu müssen.
Ich habe gesehen, dass Software, die bereits seit 10 Jahren erfolgreich eingesetzt wird, so „modernisiert“ wurde, dass die alten Designschwächen beibehalten wurden („wir müssen abwärtskompatibel bleiben“) und mit völlig anderen Architekturansätzen überformt, so dass am Ende weder der alte, noch der neue Ansatz sauber umgesetzt sind.
Ich hatte Diskussionen über den Einsatz von Tools, die ich für den angestrebten Zweck nicht benötigt habe, aber benutzen sollte, weil man das so macht und das angeblich eine saubere Methode sei.
Spätestens da klappt bei mir das Visier runter.
Ich soll Tools benutzen, obwohl ich sie aktuell nicht brauche?
Ich soll das „Framework des Tages“ nutzen, weil das gerade der heisse Scheiss ist?
Ich soll Software immer weiter abstrahieren, bis überhaupt nicht mehr erkennbar ist, an welcher Stelle eigentlich was gerade passiert?
Sorry Babe, ich bin nicht der Meinung, dass so etwas professionell ist.
Professionell ist, mit möglichst geringem Mitteleinsatz das Maximum an Output zu erzielen.
Professionell ist, Dinge so klar zu gliedern, dass im Fehlerfall sehr schnell die Ursache gefunden und behoben werden kann.
Professionell ist, Designs und Abläufe in sich stimmig zu entwerfen.
Professionell ist, unnötige Abhängigkeiten zu vermeiden
Professionell ist, Werkzeuge und Verfahren darauf zu überprüfen, ob sie die Abläufe verbessern, das Setup vereinfachen, Abhängigkeiten reduzieren und den Mitteleinsatz zu verringern oder den Output zu vergrößern.
Vom Anecken bei anderen Entwicklern
Ich wurde vor einiger Zeit gefragt, was ich von Symfony als Framework halte und der Fragende war sehr erstaunt, als er von mir die offensichtlich unerwartete Antwort bekam „sehr wenig“. Noch schlimmer: Die Frage, welches Framework gut fände habe ich mit „gar keines“ beantwortet. Und mit meiner Gegenfrage, warum er denn überhaupt ein Framework nutzen möchte und nicht lieber auf wenige, gut ausgesuchte Libraries setzt konnte er letztlich gar nichts anfangen.
Ich konnte regelrecht sehen, wie in seinem Kopf die Schublade „Kleiner Hobbyentwickler“ aufging und ich dort reingestopft wurde.
Gegen Gedankenlosigkeit und Dogmen
Natürlich ist nicht alles schlecht und es gibt tatsächlich sehr sinnvolle „Best Practices“.
Auf der Suche nach einem einheitlichen Codingstil gab es vor 15 Jahren erbitterte Grabenkäpfe mit Schwerverletzten. Heute stellt man seine IDE einfach auf „PSR-„/PSR-4“ ein und fertig.
Es macht auch wenig Sinn, lang darüber zu diskutieren, wie eine REST Schnittstelle funktioniert und der Einsatz des MVC-Patterns bei normalen Webanwendungen sehe auch ich als gesetzt an.
Was mich wirklich stört, ist nicht das einzelne Tool, sondern das Herangehen.
Wer Symfony nehmen will, soll es tun. Wer mit LESS, SASS, Grunt oder sonstigen Tools arbeiten möchte, soll es tun. Wer mit Jenkins seine Container für automatisierte Tests bauen will, der soll es tun.
Aber er sollte vorher ergebnisoffen prüfen, ob der Zusatzaufwand gerechtfertigt ist und man die Aufgaben nicht auch auf ganz andere, möglicherweise wesentlich schlankere Art lösen kann.
Diese Abwägung findet momentan einfach nicht statt. Die Diskussionen sind sehr einseitig und von Dogmen durchsetzt. Das kommt daher, dass man allen Ernstes Jobtitel wie „Software-Evangelist“ schafft.
Am 23. und 24. März fand in Jena das mittlerweile sechste eCommerce Camp statt. Auch bei meinem dritten Besuch, verlief die Veranstaltung im gewohnten Rahmen: Am Vorabend trafen sich viele der Teilnehmer nach der Anreise zum Plausch bei Bier und deftigem Thüringischen Essen in der Gaststätte zur Nöll in der Altstadt. Die eigentliche Veranstaltung fand am Freitag und Samstag Vormittag in der Ernst-Abbe Hochschule in Form einer Unconferenz statt.
Jena – Zeiss neben der Ernst Abbe Hochschule
Nach einem gemeinsamen Frühstück bildete sich die Schlange mit den Teilnehmern, die einen Vortrag oder einen Workshop vorbereitet hatten. Einer nach dem anderen trat auf die Bühne und stellte dem Saal sein Thema vor.
Die Einreichungen wurden thematisch sortiert und auf die Slots verteilt. Am Ende stand ein voller und interessanter Vortragsplan.
Unconference Programm
„Da muss der alte Mann jetzt mal selbst ran“
Im Vorjahr hatte mich der Mitveranstalter gefragt, ob ich nicht auch mal ein Thema vorbereiten möchte. In diesem Jahr nahm ich die Arbeit auf mich und habe einen Vortrag vorbereitet. Er ist betitelt „No KISS – we’re doing it wrong“ und handelt von Trends in der Softwareentwicklung, die ich für problematisch oder gar falsch halte.
Die Kernthese lautet, dass sich viele Trends etablieren, die Software sehr aufblähen, langsam und angreifbar machen und entgegen der Intention auch nicht für bessere Wartbarkeit und Wiederverwendbarkeit sorgen. Als Beispiele nannte ich u.a. fette Frameworks, unbedachter Einsatz von Libraries, Annotations, ORM, Metasprachen und zu viele Basistechnologien im Setup.
Da ich noch nie bei solch einer Veranstaltung vorne stand, war ich auch etwas nervös. Werde ich einen Hänger haben? Interessiert das Thema überhaupt jemanden? Da mein Vortrag etwas gegen den Entwickler-Mainstream gebürstet war war ich auch gespannt, ob meine Thesen in der Luft zerrissen würden. Zudem hatte ich kaum Zeit, mich seelisch vorzubereiten, weil ich gleich in den ersten Slot nach der Einführungsveranstaltung dran war.
Es stellte sich heraus, das meine Bedenken unbegründet waren. Mein Vortrag war flüssig, es waren ca. 20 Zuhörer im Raum, was für diese Veranstaltung gar nicht mal so wenig ist. Zum Ende des Vortrags kam es nochzu einer kurzen Diskussion über den einen oder anderen Punkt, aber alles in allem erntete ich viel Zuspruch, wie sich auch noch in einigen Gesprächen im Tagesverlauf zeigte.
Ein Teilnehmer meinte, dass er ähnliches in letzter Zeit häufiger gehört habe und die Kritik meist von älteren Entwicklern kämen und ob das Zufall sei. Meiner Meinung nach ist das kein Zufall, sondern es hängt damit zusammen, dass wir älteren Entwickler früher an Maschinen entwickelt habe, die sehr beschränke Ressourcen hatten. Der Rechner war immer zu langsam, hatte stets zu wenig Speicher und die Übertragungsgeschwindigkeit war immer langsam. Daher sind wir es gewohnt, auf Ressourcenverbrauch zu achten. Heutzutage spürt man zunächst keine Ressourcenknappheit. Daher ist es sehr einfach, eine Anwendung aus vorgefertigten Elementen „schnell zusammenzustöpseln“. Dass man ein Problem hat, merkt man erst, wenn unerwartet viel Traffic auf den Server einprasselt, aber dann liegt das Kind bereits im Brunnen.
Gutes Programm, spannende Gespräche
Das gute daran, den ersten Slot zu bekommen ist, dass man sich danach entspannt auf die Vorträge der anderen konzentrieren kann. Für mich aktuell einer der wertvollsten Vorträge war „MySQL Profiling“, den Andreas Ziethen von Scale hielt. Sein Vortrag setzte genau dort an, wo mein Wissen aufhörte. Nach einer Einführung in das Tool zur Auswertung von Datenbank Logfiles wurden einige Auswertungen von echten, aktuellen Problemfällen zusammen mit den Hörern vorgenommen – sozusagen Gruppendebugging.
Kontrovers diskutiert wurden die Vorschläge für eine neue Shoparchitektur, die Marcus Franke und Richard Burkhardt in der Session „E-Commerce Performance neu gedacht! Proof of Concept: Schnelle Webshops ohne Caching“. Der Wunsch, das Caching aus den Shops zu entfernen ist groß und Vorschläge dazu sehr willkommen, wie sich an recht vielen Hörern im Saal zeigte. Der präsentierte Prototyp, der eine Kategorieseite aus einem Datensatz von einer halben Million Artikeln in 0.4 Sekunden zeigte, basierte auf dem Konzept eines Application Servers, wie man ihn aus der Java Welt kennt. Aus dem Publikum kamen jedoch recht gewichtige Gegenargumente: Zweifel, ob PHP für lang laufende Prozesse stabil genug ist, hoher Ressourcenverbrauch und Fragen wie die Objektdaten im Speicher aktuell gehalten werden. Nach meiner Ansicht das stichhaltigste Argument war, dass der Showcase deshalb so schnell sei, weil alles, was einen echten Shop ausbremst (Framework, ungenutzte Features, Konfigurationsmöglichkeiten,…) nicht implementiert ist. Wenn man dasselbe mit plain PHP baut, kommt man vermutlich auf ähnlich schnelle Zeiten.
Zwar ist es nicht schön, wenn einem die eigene Arbeit so zerpflückt wird, aber die Argumente waren plausibel und der Ton kollegial. Ich finde es auf jeden Fall sehr gut, dass die beiden sich nicht nur Gedanken gemacht haben, sondern auch noch viel Zeit in einen Showcase investiert und das Ergebnis zur Debatte gestellt haben.
Ein Herz für Nerds
Das abendliche Unterhaltungsprogramm im Paradies Cafe habe ich in diesem Jahr nicht so ausgekostet, wie 2017. Ich war nicht so richtig in Feierlaune und mir schienen auch die anderen Konferenzteilnehmer in diesem Jahre etwas zurückhaltender. Das war aber nicht unbedingt von Nachteil, weil es der Konzentration am Samstag Vormittag zu Gute kam.
Simon Pearce von SysEleven zeigte, wie man mit Hilfe von Kubernetes und einigen einfachen Konfigurationsdateien in wenigen Minuten ein MySQL Datenbankcluster mit einem Master und drei Slave Nodes bauen kann. Bereits am Vortag hatte er demonstriert, wie ein Setup aus NGINX Webservers so aufgesetzt werden kann, dass bei Bedarf automatisch weitere Serverinstanzen gestartet und bei abnehmender Last wieder gestoppt werden können.
Kurz vor bevor ich zurück nach Berlin fahren wollte, bekam ich in einem sehr interessanten Gespräch nebenbei eine Vorführung eines begeisterten Shopbetreibers in Echtzeitprofiling seines Shops mit Tideways und eine Diskussion über den Umgang mit der Datenschutzgrundverordnung. Zu meiner Verblüffung erfuhr ich von einem mir bekannten Shop, der mittlerweile völlig auf die Speicherung von personenbezogenen Daten verzichtet. Das Shopsystem selber ist „clean“, so wie ich es von Bankenanwendungen kenne. Ich bin gespannt, ob sich so etwas rumspricht und durchsetzt.
Fazit
Dieses spontane Gespräch am Rand zeigt auf, was diese Veranstaltung in meinen Augen so wertvoll macht: Der spontane, offene und ehrliche Austausch über Probleme und Lösungen. Ich hoffe sehr, dass diese Veranstaltung auch in den nächsten Jahren fortgeführt wird.
Gerade macht die Aussage von George RR Martin, dem Autor von Game of Thrones, die Runde, dass er auf einem völlig veralteten Rechner schreibt (siehe BBC Artikel). Er nutzt Wordstar 4.0 auf einem Rechner unter MS-DOS.
Kopfschütteln und Lachen
Bei vielen wird er damit auf Missverständnis stoßen. In dem unten gezeigten Interview schütten sich die Zuhörer aus, vor Lachen. Er selber bezeichnet sich als Dinosaurier und bedient damit (auch optisch) das Klischee von dem alten Mann, der irgendwie stehen geblieben ist und den alten Zeiten nachtrauert.
Nicken und Zustimmung
Der Eindruck täuscht. Ich halte Martin nicht für rückständig, sondern für zielorientiert. Er fokussiert sich auf das Ziel, eine Geschichte zu schreiben. Dazu benutzt er das Werkzeug, das ihn am besten dabei unterstützt. Martin ist der Meinung, dass dieses alte System wesentlich besser dafür geeignet ist, als moderne Software auf neuen Rechnern. Als Begründung führt er vor allem die automatische Rechtschreibkorrektur an, die regelmässig seine Texte zerschreddert. Das führte im Internet zu wohlmeinenden Kommentaren, wie bei Office die Rechtschreibkorrektur auszuschalten ist. Diese Kommentare gehen aber eigentlich am Problem vorbei, denn Martin hat recht. Er ist in diesem Fall der Experte. Wer hier eindeutig nicht Experte ist:
Börsenanalysten, die Softwarefirmen bewerten
Marketing Spezialisten von Software Firmen
Produktmanager von Software Firmen
User Interface Designer bei Software
Die o.g. Personengruppen haben zum Ziel, ständig neuen Umsatz zu erzeugen, indem sie ständig neue Software auf dem Markt bringen.
Martin hingegen will nur ein möglichst effizientes Werkzeug zum Schreiben. Er sagt „I like Wordstar 4.0. It’s a word processor that does everything I need. And it does nothing else“ und bringt damit eine zunehmend problematische Entwicklung auf den Punkt:
Die digitalen Werkzeuge werden schlechter
Die Autokorrektur ist nur ein Beispiel unter vielen: Ständige Ablenkung durch aufpoppende Nachrichten, Update Meldungen, E-Mails, Twitter Nachrichten und so weiter. Permanente Nerverei durch Antiviren Software, Firewalls, Zwangsupdates, Bedienoberflächen, die alle paar Monate geändert werden, Daten die man nicht mehr lokal speichern kann, gültige URLs, die der Browser nicht akzeptiert, weil sie nicht mit www anfangen oder mit .com aufhören.
Zwang, Besserwisserei, Bevormundung, Überfrachtung, wohin man auch sieht. Und weil Computer mittlerweile in so ungefähr alles eingebaut werden, gibt es auch keine reifen Produkte mehr. Immer muss irgendwas upgedatet und ausgebessert und nachgerüstet werden. Junge Leute von heute wissen vermutlich gar nicht, dass man ein Produkt früher fertig entwickelt hat, bevor man es auf den Markt brachte.
In der Vergangenheit, haben uns Computer viel Nützliches gebracht: Bessere Produkte durch präzise Fertigung, Saubere Motoren und Heizungen durch bessere Steuerung, demokratisierung der Medienproduktion und so weiter.
Ich werde aber das Gefühl nicht los, dass sich die Entwicklung der Nützlichkeit vor einiger Zeit den Höhepunkt erreicht hat und nun eher wieder sinkt.
Gibt es neben Peak Oil vielleicht auch Peak Digital – den Zeitpunkt, ab dem es mit der Nutzung digitaler Güter wieder abwärts geht?
Nachdem ich mein kleines Spiel Colorflood für den Commodore 64 fertiggestellt hatte, lud mich Dr. Stefan Höltgen ein, darüber einen Vortrag an der Humboldt Universität zu halten. Gestern Abend war es dann soweit. Im Signallabor des Fachbereichs Medienwissenschaften sprach ich vor kleiner, aber interessierter Runde über die Entstehung des Spiels.
Ollmetzer erzählt...
Ich sprach von der Motivation, weshalb ich mich heuzutage (wieder) mit alter, einfacher Technik auseinandersetze, über Ziele und die Herangehensweise, sowie natürlich über die technische Umsetzung. Im Anschluss wurden dann noch einige Runden auf den vorbereiteten C64 und C128 gespielt. Den Abend ließen wir dann gemeinsam mit Fachgeprächen bei einem gemütlichen Umtrunk in einem nahegelegenen Restaurant ausklingen.